想象一下,您手头有一堆关于用户行为、销售数据或者实验结果的宝贵信息,您隐约觉得这些数据里藏着金矿,能揭示规律、预测未来或验证假设,如何将这些“隐约觉得”转化为坚实可靠、可供决策的洞见?答案就在于建立严谨的“实证分析模型”,尤其在人工智能(AI)时代,构建能够有效学习数据、发现模式并做出智能推断的模型,已成为驱动业务和科研的核心能力,如何一步步建立这样一个强大的AI实证分析模型呢?让我们深入探讨这个关键过程。
第一步:精准定义目标与问题(Why & What?)
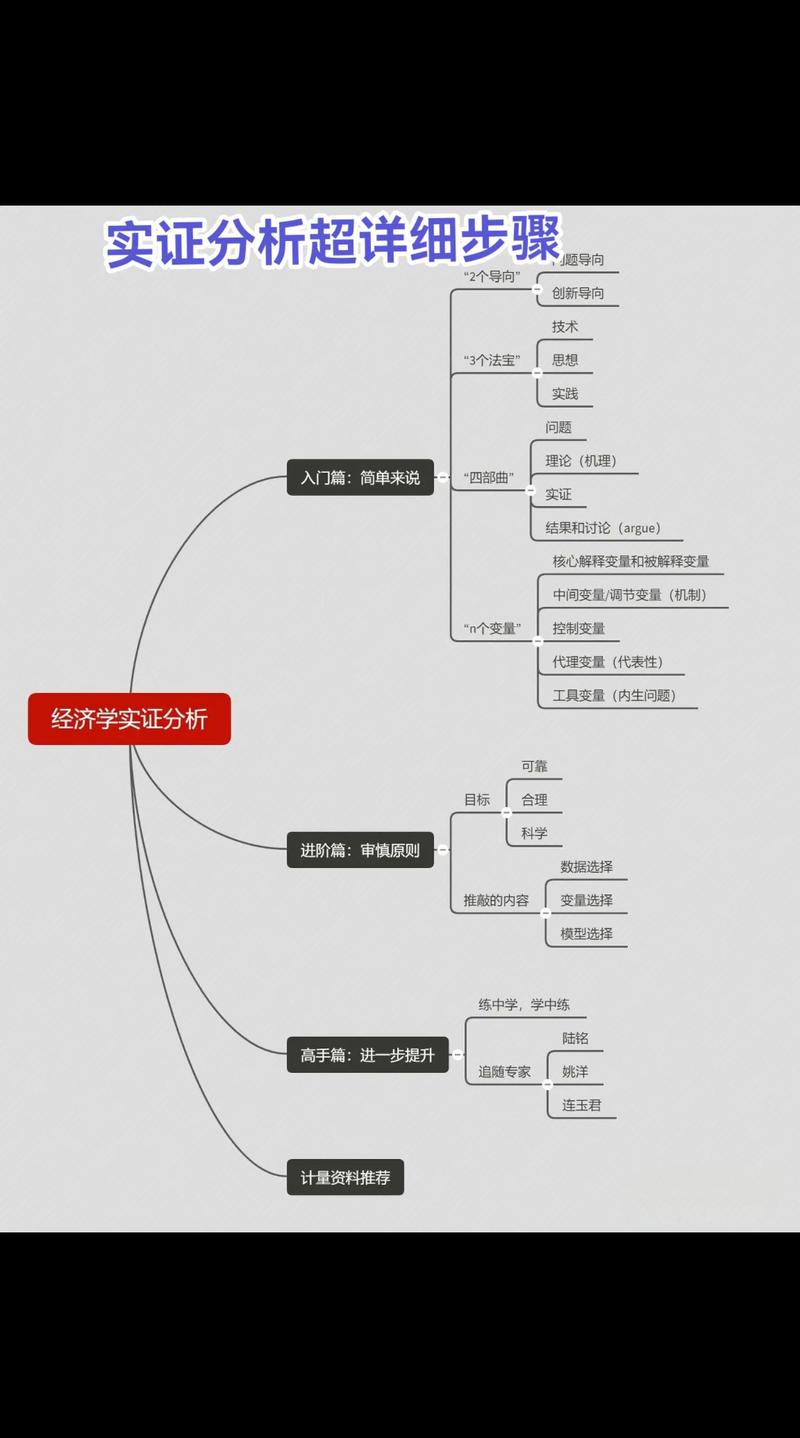
这是整个建模过程的基石,方向错了,再精妙的模型也徒劳无功,您必须清晰回答:
- 核心研究问题是什么? 是预测用户流失概率(预测性建模)?是评估某个营销活动对销售额的真实影响(因果推断)?还是探索不同用户群体的行为模式(描述性/探索性分析)?问题的性质决定了模型类型和方法论。
- 具体目标是什么? 期望模型达到什么精度?希望解释哪些关键因素?目标需要量化(如AUC达到0.85以上)或明确限定(如识别影响销量的前三大因素)。
- 可衡量的成功标准是什么? 如何判断模型是否有效?是预测准确率、召回率、R平方、业务指标提升幅度,还是模型的可解释性?提前设定标准至关重要。
第二步:数据——模型的基石(Data is King)

高质量的数据是构建可靠AI模型的前提,这一步需要投入大量精力:
- 数据收集: 识别并获取所有与研究问题相关的数据源,这可能包括内部数据库、用户日志、第三方API、调查问卷、实验数据等,确保数据覆盖了模型需要学习的各种场景和潜在影响因素。
- 数据清洗与预处理(Data Wrangling): 这是极其关键但常被低估的环节,处理缺失值(删除、填充)、识别并处理异常值、纠正数据录入错误、统一格式和单位,脏数据必然导致差模型。
- 特征工程(Feature Engineering): 这是建模的艺术与科学核心之一,基于领域知识和对问题的理解,将原始数据转化为模型更能理解的“特征”(变量),包括:
- 创建新特征: 从用户注册日期计算“用户年龄”,从购买记录计算“购买频率”和“平均客单价”。
- 特征变换: 对数值特征进行标准化/归一化(使不同量纲的特征可比)、对分类特征进行独热编码(One-Hot Encoding)或目标编码(Target Encoding)。
- 特征选择: 并非所有特征都有用,使用统计方法(如相关性分析、卡方检验)或基于模型的方法(如L1正则化、特征重要性排序)筛选出最具预测力或解释力的特征子集,减少噪声、防止过拟合、提升效率。
第三步:选择合适的模型(Choosing the Right Tool)
没有放之四海而皆准的“最佳”模型,选择取决于问题类型、数据特性及目标:
- 预测性问题:
- 回归模型(预测连续值): 线性回归(基础)、岭回归/Lasso回归(处理共线性)、决策树回归、随机森林回归、梯度提升树(如XGBoost, LightGBM, CatBoost - 通常性能优异)、支持向量回归(SVR)、神经网络(复杂模式)。
- 分类模型(预测类别标签): 逻辑回归(基础且可解释)、K近邻(KNN)、支持向量机(SVM)、朴素贝叶斯、决策树、随机森林、梯度提升树、神经网络。
- 因果推断问题: 双重差分法(DID)、倾向得分匹配(PSM)、工具变量法(IV)、断点回归设计(RDD)、结构方程模型(SEM)等,这些方法旨在更可靠地识别因果关系,而非仅仅是相关。
- 聚类/降维问题: K-Means、层次聚类、DBSCAN(聚类);主成分分析(PCA)、t-SNE、UMAP(降维可视化)。
- 考量因素:
- 数据量与维度: 小数据集可能更适合简单模型(如线性模型、决策树),大数据集和高维数据能发挥复杂模型(如深度学习)的优势。
- 可解释性要求: 若需要理解模型如何决策(如金融风控、医疗诊断),线性模型、决策树、规则模型(RuleFit)或SHAP/LIME等解释工具配合的模型更佳,复杂模型常被视为“黑箱”。
- 计算资源与效率: 训练和部署模型所需的计算成本和时间。
- 模型成熟度与社区支持: 成熟模型有更稳定的库和更丰富的经验参考。
第四步:模型训练、评估与调优(Build, Validate, Refine)
- 数据划分: 将清洗处理后的数据划分为训练集(用于训练模型)、验证集(用于在训练过程中调整超参数、选择模型)和测试集(用于最终评估模型在未见数据上的泛化能力,必须严格隔离!),常用比例如70%训练,15%验证,15%测试,或使用交叉验证。
- 模型训练: 使用训练集数据,通过算法学习特征与目标变量之间的关系,最小化预测误差(回归)或最大化分类准确率(分类)。
- 模型评估: 使用验证集评估不同模型或同一模型不同参数的性能,选择与目标匹配的评估指标:
- 回归: 均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、决定系数(R²)。
- 分类: 准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值、AUC-ROC曲线下面积,避免仅依赖准确率,尤其在数据不平衡时。
- 超参数调优(Hyperparameter Tuning): 模型本身有一些需要预先设定的参数(超参数),如学习率、树的最大深度、正则化强度等,使用验证集,通过网格搜索(Grid Search)、随机搜索(Random Search)或贝叶斯优化(Bayesian Optimization)等方法寻找最优超参数组合。
- 交叉验证(Cross-Validation): 尤其在小数据集上常用(如K折交叉验证),将训练集分成K份,轮流用其中K-1份训练,1份验证,循环K次取平均性能,更稳健地评估模型和选择超参数,减少数据划分偶然性的影响。
- 最终测试: 使用测试集(从未参与训练和调优的数据)评估最优模型的真实泛化能力,这是衡量模型最终上线价值的黄金标准。
第五步:模型解释与洞见挖掘(Understanding the Why)
模型不只是“预测机器”,更是理解世界的窗口,尤其对于需要决策支持的场景,解释性至关重要:
- 全局解释: 模型整体上哪些特征最重要?特征与目标变量的大致关系如何?(如特征重要性排名、部分依赖图PDP)。
- 局部解释: 对于单个样本的预测结果,是哪些特征及其取值导致了这样的预测?(如SHAP值、LIME),这有助于理解个案、发现异常或验证逻辑。
- 洞见转化: 将模型揭示的统计规律和关系,结合业务知识或领域常识,转化为可操作的洞见和建议,模型发现“用户访问频率”是留存的关键预测因子,那么提升用户活跃度的策略就具有高优先级。
第六步:部署、监控与迭代(From Lab to Real World)
模型通过测试评估后,旅程并未结束:
- 模型部署: 将模型集成到生产环境(如网站推荐系统、风控引擎、预测API),使其能够实时或批量处理新数据并输出结果,这涉及工程化工作(容器化、API开发、性能优化)。
- 持续监控: 上线后必须持续监控模型性能(如预测准确性、延迟、资源消耗)和输入数据的分布,现实世界的数据会变化(数据漂移),模型性能可能随时间下降。
- 定期评估与迭代: 设定重新评估模型的周期,当性能显著下降或业务需求变化时,需要触发模型的重新训练(使用新数据)、重新调优,甚至重新设计,模型的生命周期是迭代的。
挑战与注意事项
- 数据质量永远第一: 垃圾进,垃圾出(GIGO),投入不足会导致模型失败。
- 过拟合(Overfitting)与欠拟合(Underfitting): 模型在训练集上表现太好(记忆噪声)或在训练集上都表现差(未学到规律),通过正则化、交叉验证、调整模型复杂度(如剪枝)来平衡。
- 因果与相关陷阱: 实证模型(尤其预测模型)主要揭示相关关系,得出因果结论需极其谨慎,通常需要专门设计的因果推断方法或严格的实验(如A/B测试)。
- 伦理与偏见: AI模型可能放大数据中存在的偏见,导致不公平结果,需主动检测和缓解偏见,考虑模型的伦理影响。
个人观点: 建立有效的AI实证分析模型绝非简单的技术堆砌,它是一门融合了严谨科学方法、深刻领域认知和务实工程实践的综合性技艺,成功的关键在于对问题本质的精准把握、对数据质量的锱铢必较、对模型选择与评估的审慎权衡,以及将统计结果转化为实际价值的洞察力,模型是服务于认知和决策的工具,其价值最终体现在它如何帮助我们更清晰、更可靠地理解这个复杂世界并做出更优的选择,持续学习、保持批判性思维,并拥抱迭代改进,是在这个数据驱动时代驾驭AI实证分析力量的不二法门。

 13888888888
13888888888

 点击咨询
点击咨询 