在人工智能技术飞速发展的今天,大型AI模型已成为许多行业的核心驱动力,许多人都好奇,这些模型究竟是如何从海量数据中汲取知识,进而完成各种复杂任务的,理解这一过程,不仅有助于我们更好地应用AI技术,也能帮助我们在日益智能化的世界中保持清晰的认知。
AI大模型学习数据的过程,并非一蹴而就,而是一个系统且多阶段的工程,整个过程可以大致分为几个关键步骤:数据收集与清洗、模型预训练、微调优化以及最终的性能评估与部署。
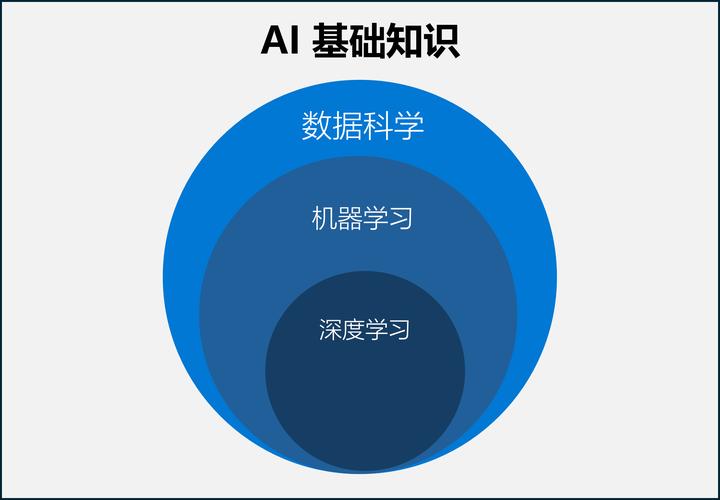
数据的质量直接决定了模型能力的上限,用于训练的数据通常来源于公开数据集、经过授权的网络文本、书籍、论文等多种渠道,这些原始数据往往包含大量噪声、重复或低质量内容,因此必须经过严格的清洗和预处理,数据清洗包括去除无关字符、标准化文本格式、过滤敏感信息等一系列操作,以确保输入模型的信息具备一致性和可用性,只有在高质量数据的基础上,模型才能开展有效的学习。
接下来是模型的核心学习阶段——预训练,在这一过程中,模型通过自监督学习的方式,借助海量文本数据来构建对语言的基本认知,以当前主流的大语言模型为例,它们通常采用Transformer结构,通过注意力机制捕捉文本中长距离的依赖关系,训练时,模型尝试根据上文预测下一个词,或通过掩码语言建模的方式还原被遮盖的词语,通过数十亿甚至万亿次这样的预测任务,模型逐渐掌握语法结构、常见知识以及一定的逻辑推理能力。
值得注意的是,预训练阶段并不赋予模型“理解”的能力,而是让它学会统计层面的语言模式,它能够识别出哪些词经常共同出现,哪些句式更常见,但却并不真正“懂得”文字背后的含义,这一点非常重要,有助于我们客观看待模型的能力边界。
完成预训练后,模型虽然已经具备强大的语言生成能力,但还不足以精准完成特定任务,例如客服问答、代码生成或医疗建议,此时就需要微调阶段进一步优化,微调是指在特定任务数据集上对预训练模型进行有监督的训练,为了让模型学会更好地回答问题,研究人员会使用大量人工标注的问答数据对模型进行训练,通过梯度下降算法调整模型参数,使其输出更符合任务要求。
为了提高模型的可用性和安全性,通常会引入人类反馈强化学习(RLHF)技术,通过让人类标注员对模型的不同输出进行评分,训练一个奖励模型,进而使用强化学习算法引导模型生成更符合人类偏好和价值观的内容。
模型的训练并非一次完成,而需要多次迭代和调优,研究人员会持续评估模型在各类基准测试中的表现,分析其错误案例,进一步调整模型结构或训练策略,这种持续优化机制,使得大模型能不断适应新的需求和应用场景。
纵观整个学习过程,AI大模型依赖的是极其复杂的数学计算和海量数据的统计规律,而非人类意义上的“学习”或“思考”,它的能力源于高质量的数据、精心设计的算法以及巨大的算力支持,作为网站站长,我始终认为,虽然人工智能技术发展迅猛,但其本质仍是人类智慧的延伸,真正推动进步的,始终是那些不断探索、持续创新的研究者与工程师,我们既要积极拥抱技术带来的便利,也需清醒认识到其局限性,这样才能更好地将其应用于实际场景,服务于更广泛的社会需求。

 13888888888
13888888888

 点击咨询
点击咨询 