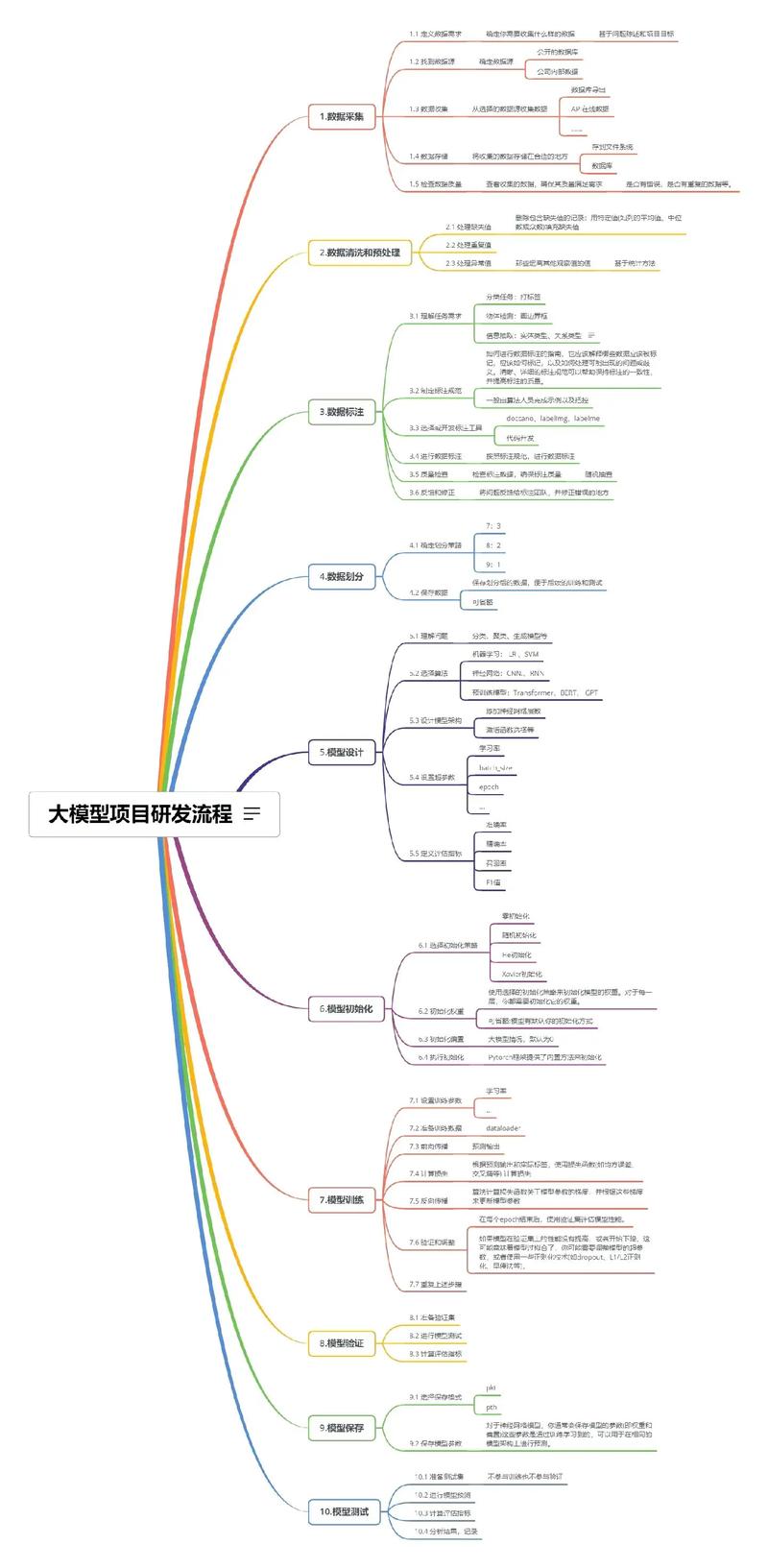
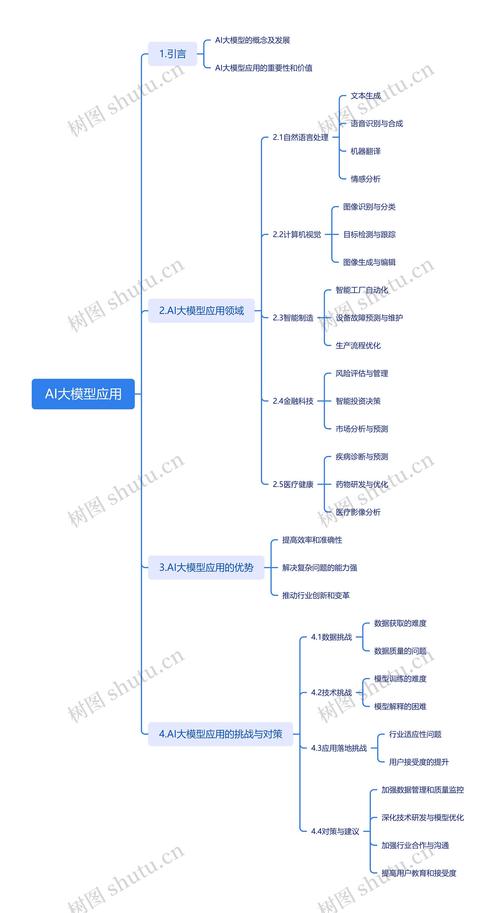
面对AI大模型的浪潮,很多人感到无从下手:技术门槛高、领域发展快、知识体系庞杂,研究大模型并非高不可攀,关键在于找到一条清晰的路径,以下是一套循序渐进的研究方法,旨在帮助初学者和从业者系统性地构建认知与实践能力。
第一阶段:建立认知基础——从理解“是什么”开始
研究的第一步是放下焦虑,不必强求立即掌握所有技术细节,首要任务是建立宏观认知。
-
明确核心概念:准确理解“大模型”究竟是什么,它通常指通过在海量数据上训练,拥有庞大参数规模(数十亿至数万亿)的深度学习模型,具备强大的语言理解、生成和推理能力,厘清与之相关的术语,如Transformer架构、注意力机制、预训练、微调、提示工程等,这些是后续学习的基石。
-
追踪行业动态与思想领袖:关注该领域的顶级学术会议,如NeurIPS、ICLR、ACL等,了解最新的研究进展,在社交媒体(如X/Twitter、知乎)上关注一些顶尖的AI科学家、工程师和重要机构的官方账号,他们的分享往往包含了前沿的思考、论文解读和行业趋势,能帮助你保持信息敏感度。
-
阅读高质量的科普与综述:在深入技术论文之前,先从一些优秀的行业分析报告、深度科普文章入手,它们能帮助你快速了解整个领域的技术演进脉络、主要玩家、应用场景和未来挑战,构建起一个完整的知识框架。
第二阶段:动手实践——在“用”中学
理论必须结合实践,对于大模型研究,动手操作是深化理解不可或缺的环节。
-
亲身体验各类模型:直接去使用主流的AI产品,例如ChatGPT、文心一言、通义千问、Kimi等,不要仅限于简单问答,尝试进行复杂的对话、逻辑推理、内容创作和代码编写,记录不同模型的特点、优势和劣势,形成直观感受。
-
掌握提示工程技能:提示工程是与大模型交互的核心技能,学习并实践各种提示技巧,如思维链、角色扮演、零样本/少样本提示等,通过精心设计提示词,你能更有效地激发模型的潜力,完成更复杂的任务,这个过程会让你深刻理解模型的行为模式和局限性。
-
运行开源模型:当具备一定基础后,可以尝试在本地或云端服务器上部署和运行开源模型(如Llama、Qwen、ChatGLM等),从HuggingFace等平台下载模型,学习使用其Transformers库进行简单的文本生成、情感分析等任务,这个过程会让你对模型的加载、推理和硬件需求有切身体会。
第三阶段:深化理论理解——探究核心原理
在有了感性认识和实践经验后,回归理论,探究其运行机制,将使你的研究水平实现质的飞跃。
-
精读奠基性论文:不必贪多,选择几篇开山之作进行精读,Attention Is All You Need (Transformer)、BERT、GPT系列论文等,第一遍可以重点关注其摘要、引言和结论,理解他们要解决什么问题,提出了什么方法,达到了什么效果,第二遍再尝试深入理解模型架构图和核心公式。
-
学习相关的在线课程:斯坦福、麻省理工等顶尖学府,以及国内外众多高校和机构都发布了优秀的AI课程视频,选择一门系统讲解自然语言处理或大模型的课程,跟随权威教授的讲解,能够帮你梳理知识体系,弥补自学可能出现的漏洞。
-
关注技术报告与博客:像OpenAI、Google DeepMind、Anthropic等机构发布的技术报告和博客,通常比学术论文更侧重于工程实现、模型能力和安全伦理的宏观阐述,是理解顶级模型设计理念的绝佳资料。
第四阶段:聚焦细分领域——形成个人专长
大模型生态极其丰富,试图掌握所有方面是不现实的,在广泛了解后,需要选择一个方向进行深度钻研。
- 模型架构与优化:深入研究如Mixture of Experts (MoE)等新型架构,或量化、剪枝、蒸馏等模型压缩与加速技术。
- 对齐与安全:研究如何让模型的行为与人类价值观和意图保持一致,包括RLHF、RLAIF,以及如何防范模型产生偏见、虚假信息等风险。
- 多模态融合:探索文本、图像、音频、视频如何在一个统一的模型框架下进行理解和生成。
- 特定领域应用:将大模型技术与金融、医疗、法律、教育等垂直行业相结合,解决实际业务问题。
- Agent(智能体)技术:研究如何让大模型具备使用工具、规划步骤、与环境交互以完成复杂任务的能力。
确定方向后,可以尝试复现经典论文的代码、参与开源项目、或在Kaggle等平台参加相关竞赛,将理论知识转化为解决实际问题的能力。
关于研究心态的几点个人看法:
研究AI大模型是一场马拉松,保持持续的好奇心和学习的韧性,比短期内掌握多少知识更为重要,这个领域日新月异,今天的前沿可能明天就成为常识,因此建立快速学习的能力和一套属于自己的信息筛选体系至关重要,要始终保持批判性思维,不盲目相信模型的输出,也不轻信未经证实的炒作,理解其强大能力的同时,更要清醒地认识到其当前的技术边界与潜在的社会影响,研究的目的不仅是跟上潮流,更是为了能够运用这项变革性技术,去创造真实的价值。

 13888888888
13888888888

 点击咨询
点击咨询 