人工智能技术逐渐渗透到生活的各个角落,从手机语音助手到医疗影像分析,支撑这些应用的核心正是AI模型,本文将用通俗易懂的方式,揭示AI模型从无到有的完整构建过程。
模型构建的基石:数据准备 专业团队通常需要花费60%以上的时间处理数据,以医疗影像识别模型为例,工程师需要收集数十万张标注精确的X光片,这些数据需经过三阶段处理:首先进行像素级筛查,剔除模糊或标记错误的图像;接着通过图像增强技术,对病灶区域进行对比度强化;最后将数据按7:2:1的比例分割为训练集、验证集和测试集,全球顶尖实验室普遍采用分布式存储系统,确保TB级数据的安全性与调用效率。
架构设计的艺术 选择模型架构如同建造摩天大楼前的蓝图设计,卷积神经网络(CNN)在图像处理领域表现出色,其分层结构能自动提取边缘、纹理等特征;Transformer架构则凭借注意力机制,在自然语言处理任务中完胜传统模型,2023年MIT研究团队提出的HybridNet,将CNN与Transformer结合,在自动驾驶场景中实现98.7%的障碍物识别准确率。
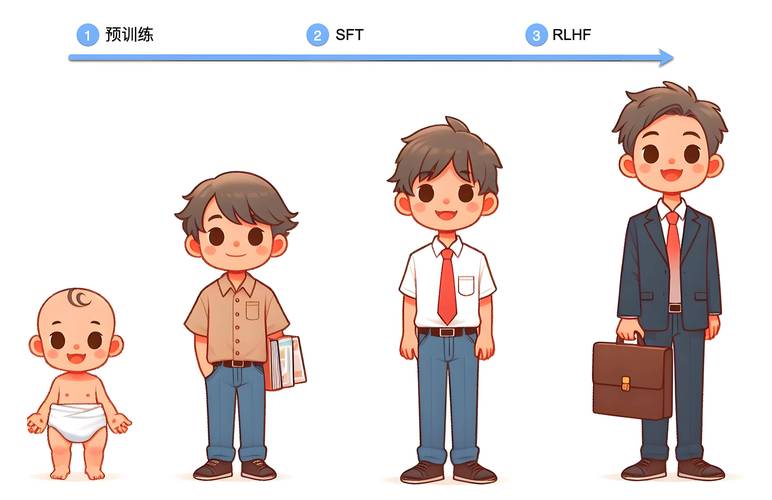
训练过程的精妙调控 模型训练不是简单的数据灌输,工程师需要精细调节学习率、批次大小等超参数,这个过程堪比交响乐指挥,采用自适应优化算法AdamW,可使模型在初期快速收敛,后期平稳调整,梯度裁剪技术能有效防止参数爆炸,正则化方法如Dropout则以15%-30%的概率随机屏蔽神经元,增强模型泛化能力,Google Brain团队曾通过动态学习率调整,将BERT模型的训练时间缩短40%。
性能验证的科学方法 模型评估需要多维度验证指标交叉检验,分类任务常用混淆矩阵结合F1-score,回归任务则侧重MAE和RMSE,在金融风控领域,AUC-ROC曲线能直观反映模型区分正常交易与欺诈行为的能力,跨数据集测试是检验泛化性的关键步骤,Kaggle竞赛优胜方案往往在5个以上不同分布的数据集上进行验证。
部署落地的工程挑战 将实验室模型转化为生产系统需要克服多重障碍,模型压缩技术如知识蒸馏,可将百亿参数的大模型精简为原体积的1/10;量化训练则把32位浮点数转换为8位整数,在保持95%精度的前提下提升推理速度,边缘计算设备采用TensorRT等优化框架,使智能手机也能流畅运行图像分割模型。
持续学习的进化之路 部署后的模型需要建立更新机制,在线学习系统通过实时数据流微调模型参数,联邦学习技术在保护隐私的前提下,利用分布式设备协同训练,2024年OpenAI推出的Evolver系统,可实现模型架构的自主进化,在对话系统中自然过渡到新知识领域。
人工智能模型的构建融合了数学理论、工程实践和领域知识的深度交叉,当看到智能客服准确理解用户意图时,这背后是数百次算法迭代与持续优化的成果,技术发展的速度远超想象,但比追求更高准确率更重要的,是确保每行代码都承载着对社会责任的思考——这才是真正意义上的人工智能进化论。

 13888888888
13888888888

 点击咨询
点击咨询 