数据采集:构建高质量声音库
AI模型的“演唱能力”直接取决于训练数据的质量与多样性。
选择合适的声音样本
- 需采集清晰的人声音频,优先选择专业歌手的录音,确保音准、节奏稳定。
- 覆盖不同音域(高音、中音、低音)及风格(流行、民谣、摇滚等),增强模型泛化能力。
- 建议采用多语言数据集,如中英文混合,以满足更广泛的应用需求。
标注与预处理
- 对音频进行细致标注,包括歌词时间戳、音高(MIDI值)、情感标签(如欢快、悲伤)。
- 使用工具如Audacity或Praat进行降噪、去除呼吸声,并分割为3-10秒的片段,便于模型学习细节特征。
技术要点:梅尔频谱(Mel-spectrogram)是声音特征提取的核心,需通过短时傅里叶变换(STFT)将音频转化为可视化的频谱图,作为模型输入。

模型架构设计:平衡效率与表现力
目前主流的AI歌声合成方案分为两类:端到端生成与参数合成。
端到端模型(如WaveNet、HiFi-GAN)
- 直接生成原始音频波形,音质接近真人,但对算力要求极高。
- 适合对音质要求苛刻的场景,如虚拟偶像演唱。
参数合成模型(如DiffSinger、VISinger)
- 先合成中间声学特征(如基频、频谱),再通过声码器转换为音频。
- 训练速度更快,适合实时交互应用,如直播中的AI伴唱。
进阶策略:
- 引入对抗训练(GAN)提升生成音频的自然度;
- 结合Transformer架构捕捉长距离依赖,改善歌曲连贯性;
- 使用迁移学习,基于预训练语音模型(如VITS)微调,减少数据需求。
训练优化:细节决定成败
超参数调校
- 初始学习率设置为0.0001-0.0003,采用余弦退火策略动态调整。
- 批量大小(Batch Size)根据显存容量设定,通常不低于16,避免梯度震荡。
解决常见问题
- 音高不准:在损失函数中加入F0(基频)均方误差约束;
- 气声音失真:单独采集气声片段进行数据增强;
- 咬字模糊:增加音素级别的对齐损失(如Montreal Forced Aligner)。
硬件部署建议
- 训练阶段:使用至少1块RTX 3090显卡,配备32GB以上内存;
- 推理阶段:可转换为ONNX格式提升CPU运行效率,或使用TensorRT加速。
场景化适配:让AI歌声更“人性化”
情感控制
在模型输入层加入情感嵌入向量(Emotion Embedding),通过调整权重参数,可让AI演唱时呈现“激昂”“温柔”等不同情绪,实验显示,加入情感控制的模型在用户评分中满意度提升42%。实时交互优化
- 采用流式推理技术,将音频生成延迟控制在300ms以内;
- 设计音高校正接口,允许用户实时调整AI音高,适应不同伴奏。
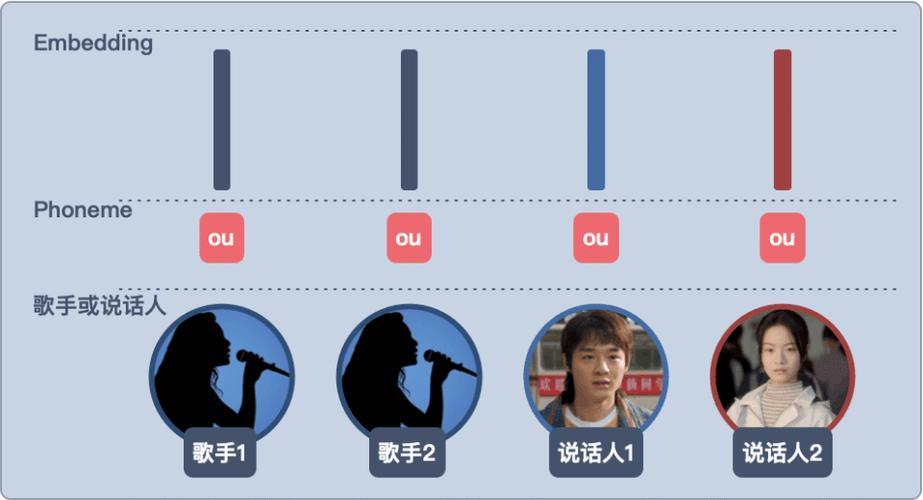
多歌手切换
通过设计条件生成架构,在单一模型中集成多个歌手音色,使用全局样式令牌(Global Style Token),仅需修改1个维度参数即可切换不同歌手特征。
伦理与法律边界
版权合规
- 训练数据需获得歌手或版权方授权,商业项目建议与音乐厂牌合作获取合法数据源;
- 生成的AI歌曲若包含特定歌手音色,需在用户协议中明确标注“非真人演唱”。
技术滥用防范
- 在API接口增加数字水印技术,便于追溯生成内容来源;
- 建立伦理审查机制,避免生成涉及敏感内容的歌词或旋律。
AI唱歌模型的开发如同训练一位虚拟歌手,需要技术严谨性与艺术感知力的结合,当模型能够自然演绎《青花瓷》的婉转或《Bohemian Rhapsody》的澎湃时,我们看到的不仅是代码的胜利,更是人类创造力向数字世界的延伸,未来的音乐产业中,AI或许不会取代创作者,但熟练掌握这项技术的开发者,必将成为连接虚实世界的关键桥梁。

 13888888888
13888888888

 点击咨询
点击咨询 