训练自己的AI模型听起来高大上,但别担心,它不像火箭科学那样遥不可及,作为一名在AI领域摸爬滚打多年的从业者,我见过太多新手从零开始,一步步打造出实用模型的故事,这不仅能提升你的技术能力,还能为个人项目或小生意带来创新动力,我就来分享一套实操指南,让你避开弯路,轻松上手,核心在于动手实践——光看书本可不够,得亲自动手试错。
理解AI模型训练的基础
AI模型本质上是一个算法系统,通过数据“学习”模式并做出预测或决策,训练过程就是喂给它大量数据,让它反复调整内部参数,直到能准确完成任务,常见类型包括图像识别、文本生成或推荐系统,选择哪种模型取决于你的目标:想做个聊天机器人?那就选生成式模型;想预测股票趋势?回归模型更合适,别急着跳进复杂框架,初学者从简单分类任务开始,比如用鸢尾花数据集区分不同花种,这能帮你打好基础。
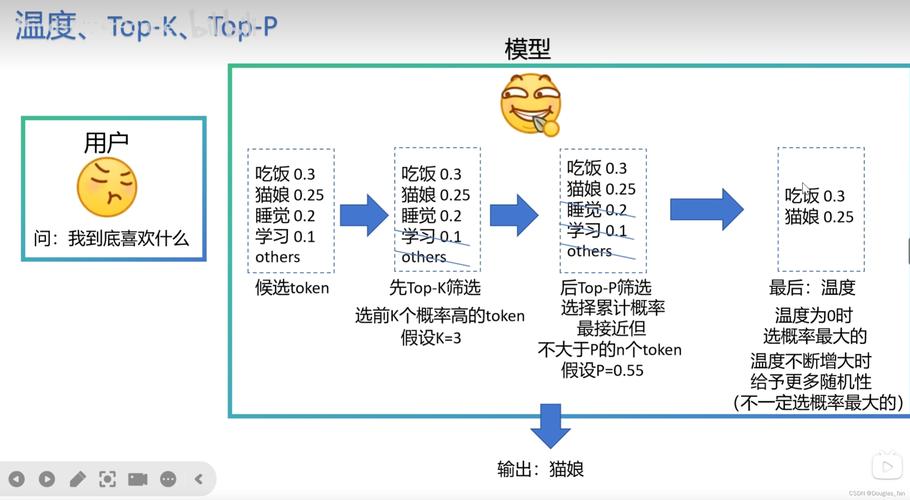
第一步:准备高质量数据
数据是AI的“燃料”,没它寸步难行,我建议从公开数据集入手,比如Kaggle或UCI Machine Learning Repository,它们提供免费、干净的样本,假设你想训练一个识别猫狗图片的模型,先收集至少1000张图片——猫狗各半,确保多样性和平衡性,数据预处理是关键:清洗掉模糊或重复图像,调整大小到统一格式(如224x224像素),并标注好标签,用Python库如Pandas处理表格数据,或用OpenCV处理图像,简单几行代码就能搞定,常见错误是数据太少或不均衡,这会导致模型偏袒某一类,多花时间在这步,能省掉后期大麻烦。
第二步:选择合适的工具和框架
工具选对了,训练效率翻倍,主流框架如TensorFlow或PyTorch免费且社区强大,我偏爱PyTorch,因为它更灵活,适合快速原型开发,安装时,用Anaconda管理Python环境,避免版本冲突,对于新手,Google Colab是福音——它提供免费GPU,直接在浏览器运行代码,无需本地配置,写代码时,从简单模型结构开始:比如用Keras构建一个卷积神经网络(CNN)处理图像,示例代码:导入PyTorch库,定义网络层、损失函数和优化器,别追求复杂架构,先用两层神经网络练手,效果满意后再升级。

第三步:实际训练模型
这是核心环节,需要耐心和监控,将数据分成训练集和测试集(比例70:30),防止过拟合,启动训练循环:模型读取数据,计算预测误差,反向传播调整参数,设置合理超参数:学习率初始值0.001,批次大小32,迭代次数10-20轮,用GPU加速训练(Colab自动支持),时间缩短几倍,过程中,实时监控指标:准确率、损失值曲线,如果损失值不下降,说明模型没学好——试试调整学习率或增加数据量,训练完成后,在测试集上评估性能:准确率达到90%以上算不错,保存模型为文件,方便后续使用。
应对常见挑战
训练路上坑不少,但都有解法,数据不足?用数据增强技术:旋转、裁剪图片生成新样本,模型过拟合?添加Dropout层或正则化,硬件限制?优先用云端服务如AWS免费层,调试时,逐层检查输出,工具如TensorBoard可视化过程,我见过新手因忽视验证集而失败——坚持用独立测试集,避免自欺欺人,遇到瓶颈别灰心,参考社区论坛如Stack Overflow,高手们乐于分享经验。
部署和维护
模型训练好只是开始,部署到实际应用才算完整,简单方式:封装成API用Flask框架部署本地服务器,或上传到Hugging Face平台分享,监控模型表现:上线后收集新数据,定期重训练防止性能退化,AI模型是“活”的系统,需持续喂养新数据来适应变化。
训练自己的AI模型不是魔法,而是一项可掌握的技能,从我的经验看,坚持小步快跑——选简单项目,动手实验,迭代优化——普通人也能成为AI高手,技术门槛在降低,工具日益友好,别让恐惧拦住你,拥抱这个过程,它不仅是技术提升,更是思维锻炼,未来属于会创造AI的人,你完全可以成为其中一员。(字数约1100字)

 13888888888
13888888888

 点击咨询
点击咨询 