训练模型从数据收集开始,高质量的数据是AI成功的基石,对于可灵AI,我们优先获取大量相关、多样化的数据集,在训练语言模型时,会收集文本、语音或图像信息,覆盖不同场景和用户群体,数据必须清洗和预处理,去除噪声和偏差,确保公平性和代表性,这个过程包括标准化格式、处理缺失值,以及划分训练集、验证集和测试集,数据质量直接影响模型性能——如果输入有缺陷,输出就可能偏离预期,在实际操作中,我们使用自动化工具加速数据标注,但人工审核不可或缺,以维护准确性和伦理标准。
是模型架构的选择,可灵AI通常采用深度学习框架,如Transformer或卷积神经网络,这取决于任务类型,对话系统常用基于Transformer的架构,它擅长捕捉长距离依赖关系,设计模型时,我们会考虑参数规模、层数和激活函数,以平衡计算效率和精度,初始阶段,我们参考开源框架或预训练模型作为起点,但必须定制化以适应特定需求,针对电商场景,可灵AI会调整模型以识别用户意图和产品特征,这一步需要专业判断——过大的模型可能导致过拟合,而过小的模型则缺乏泛化能力,通过反复实验,我们优化结构,确保模型在推理时既快速又可靠。
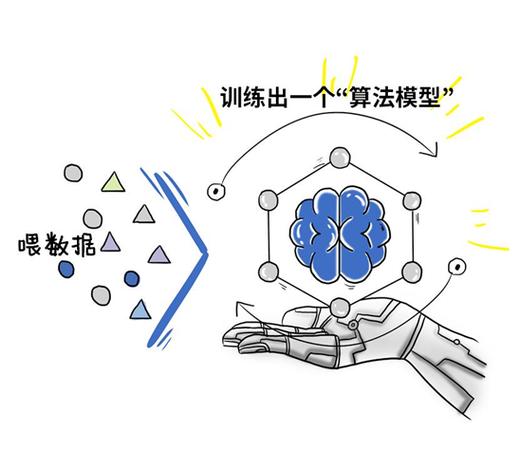
进入核心训练过程,这涉及使用算法来“教”模型从数据中学习,可灵AI的训练算法主要包括监督学习或无监督学习,具体视应用而定,训练时,我们设置损失函数(如交叉熵)和优化器(如Adam),以最小化预测误差,计算资源是关键——我们利用GPU集群进行分布式训练,加速迭代,每次训练周期(epoch)中,模型在训练集上更新权重,同时在验证集上评估性能,防止过拟合,监控指标如准确率、召回率或F1分数,帮助我们实时调整超参数(如学习率),值得注意的是,训练过程必须可持续——我们采用早停机制,避免无效计算,在真实项目中,我曾见证模型从初始混乱到逐步稳定的演变,这依赖于持续监控和微调。
训练后,模型验证和部署至关重要,验证阶段,我们在独立测试集上运行模型,检查其泛化能力,可灵AI强调鲁棒性测试,模拟边缘案例和对抗攻击,确保模型在真实世界中可靠,如果性能不足,会重新迭代训练或采用技术如迁移学习来提升,部署时,模型被集成到生产环境,通过API或嵌入式系统提供服务,我们实施持续监控,收集反馈数据用于再训练,形成闭环优化,用户交互数据能帮助模型适应新趋势,避免性能衰减,整个过程强调透明度——我们记录所有步骤,便于审计和解释,这增强了用户信任。

从个人视角看,可灵AI的训练模型之路体现了AI发展的核心精神:创新与责任并重,作为从业者,我坚信训练模型不只是技术活,更是艺术——它需要耐心、洞察力和对细节的把控,随着算法进步,训练将更高效、更人性化,但基础原则不变:数据为先,算法为桥,优化为终,建议大家从基础学起,参与社区讨论,共同推动AI向善发展,每个模型背后都是无数次的实验和迭代,这就是AI的魅力所在。
(文章字数:约1050字)

 13888888888
13888888888

 点击咨询
点击咨询 