在人工智能时代,AI模型已成为许多领域的核心工具,从医疗诊断到金融预测,模型的表现直接影响决策质量,要真正判断一个AI模型的能力,关键在于如何进行严谨的评估,许多开发者或团队在撰写评估报告时,容易忽略细节,导致结果不全面或误导,作为在AI领域工作多年的从业者,我将一步步解释如何写出一份专业的AI模型能力评估报告,确保它清晰、可信且易于理解,本文基于实际经验,旨在帮助您避免常见陷阱。
评估过程始于明确目标,在开始任何测试前,必须定义模型的具体应用场景和期望性能,如果您评估一个自然语言处理模型用于客服聊天机器人,目标可能是提高用户满意度并减少响应错误率,这一步避免盲目测试,确保评估聚焦于核心需求,列出关键问题:模型要解决什么任务?性能指标如何与业务目标对齐?在我的项目中,我常看到团队跳过此步,导致评估偏离实际应用,浪费资源,花时间撰写目标部分,用简洁语言描述,如“本评估旨在验证模型在情感分析任务中的准确性和鲁棒性”。
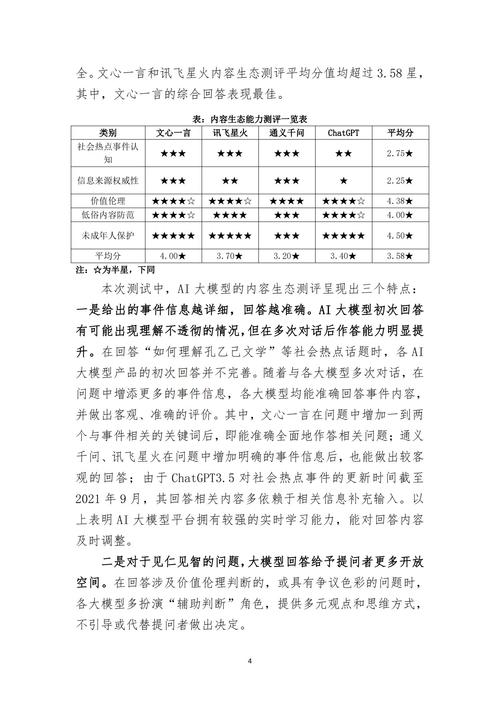
选择合适的评估指标至关重要,指标是衡量模型能力的量化工具,不同任务需不同方法,对于分类任务,常用指标包括准确率、召回率、F1分数和AUC-ROC曲线;回归任务可能关注均方误差或R平方值,公平性指标如群体差异率也应纳入,确保模型无偏见,撰写时,详细解释每个指标的含义和应用。“准确率表示正确预测的比例,但高准确率不一定代表模型可靠——需结合召回率评估漏检风险”,在我的经验中,新手常依赖单一指标,这掩盖了深层问题,推荐使用多指标组合,并在报告中附上计算方法和数据来源,增强专业性。
数据准备是评估的基石,测试数据必须真实、多样且无污染,划分数据集为训练集、验证集和测试集,测试集应独立于训练过程,防止过拟合,数据需代表实际场景:包括边缘案例和异常值,撰写此部分时,描述数据收集过程、清洗步骤和划分比例。“测试集包含10,000条用户查询,覆盖多种语言和语境,确保模型泛化能力”,我见过评估失败案例,因使用不具代表性数据,导致模型上线后性能骤降,强调数据质量,并建议进行敏感性分析,如添加噪声测试模型稳定性。
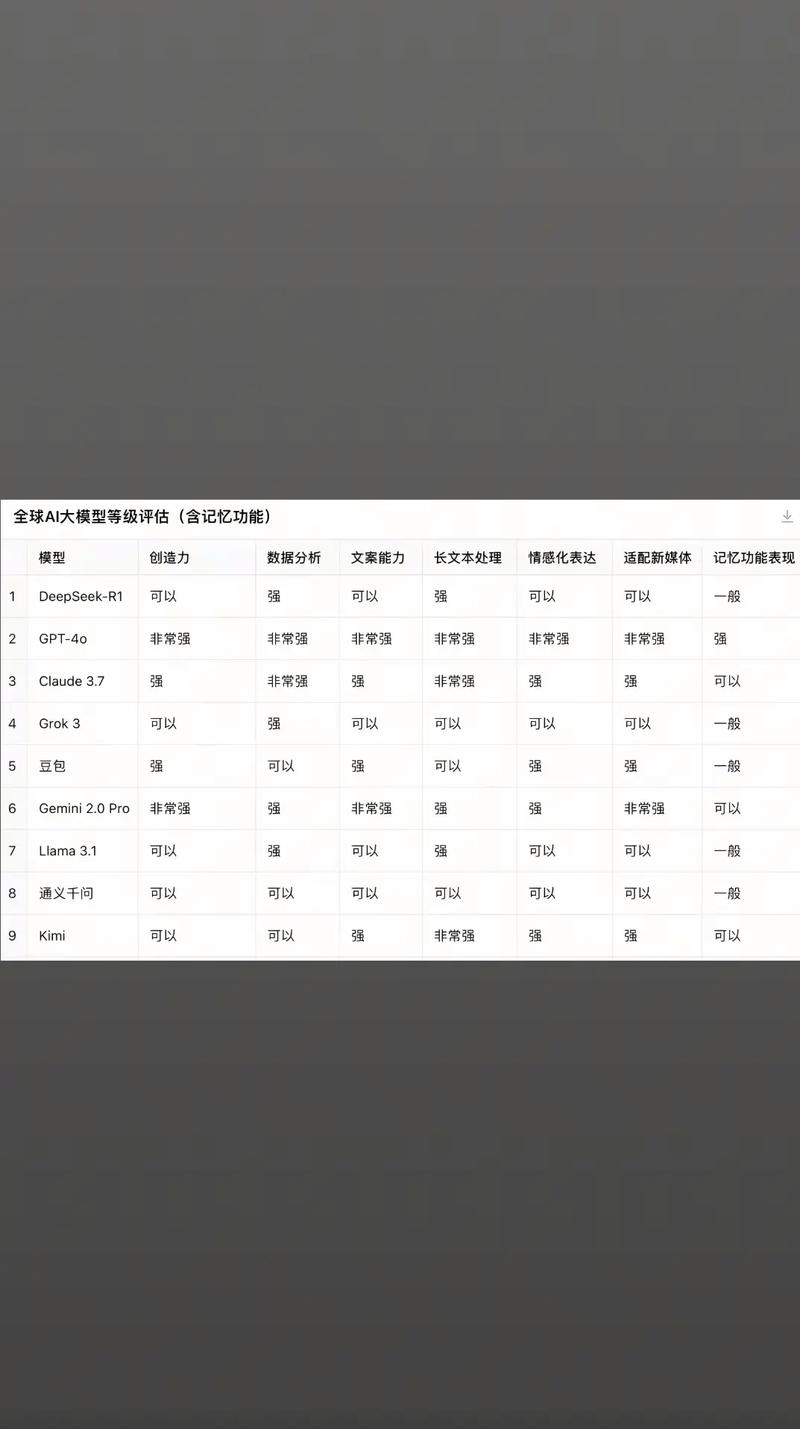
执行测试阶段,需要系统化方法,运行模型在测试集上,记录所有输出和错误,使用可视化工具如混淆矩阵或PR曲线展示结果,便于直观理解,自动化测试脚本可提高效率,但手动检查关键案例也不可少,撰写时,分步说明测试流程:环境设置、运行参数、结果记录。“在Python环境中,使用sklearn库计算指标,并保存日志供复查”,实际测试中,我坚持多次迭代测试,确保结果可复现,这步常被简化,但详细报告能提升可信度。
分析结果是评估的核心环节,不要只呈现数字,而要解读含义:模型优势在哪?弱点是什么?潜在风险如偏差或安全漏洞?如果召回率低,说明模型漏检多,需优化数据或架构,公平性分析应检查不同群体间的差异,撰写时,用数据支撑结论,避免主观臆断,结合案例,“在医疗影像模型中,我们发现特定人群准确率下降,建议增加多样性训练数据”,我的观点是,分析应透明公开失败点——这建立信任,并指导改进。
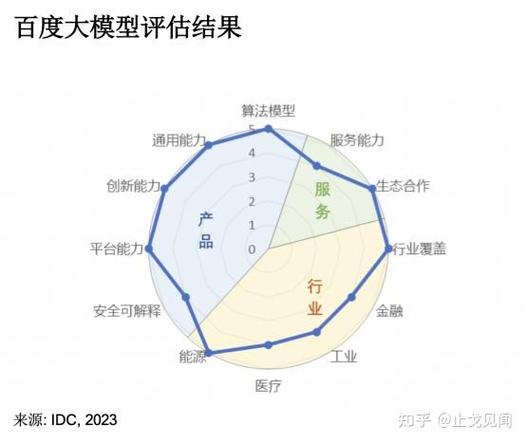
撰写报告本身需结构化且易读,报告框架包括:简述评估目标、关键结果和建议。
- 方法:详细描述目标、指标、数据及测试流程。
- 结果:展示指标数据、可视化图表和主要发现。
- 讨论:分析结果含义、局限性和改进建议。
- 附录:添加代码、数据样本或额外细节。 保持语言简洁,避免技术术语堆砌;用图表辅助,但确保文字解释清晰,在团队协作中,我强调报告的可读性——非专家也能理解,这促进决策。
AI模型评估不是终点,而是持续优化的起点,一个优秀的报告能推动模型迭代,减少现实风险,作为实践者,我坚信透明、全面的评估是AI成功的核心,忽视这一步,可能导致技术债积累,最终损害用户体验,坚持严谨方法,您将写出有价值的评估,为创新铺路。

 13888888888
13888888888

 点击咨询
点击咨询 