在当今人工智能技术迅速发展的时代,AI语言模型已成为许多应用的核心组成部分,从智能助手到自动翻译,再到内容生成,其影响力无处不在,许多人对这类模型的构建过程感到好奇,本文将简要介绍AI语言模型的基本制作流程,并分享一些相关思考。
制作AI语言模型的第一步是确定目标和范围,语言模型可以设计用于多种任务,如文本生成、问答系统或情感分析,明确模型的应用场景有助于指导后续数据收集和模型设计的方向。
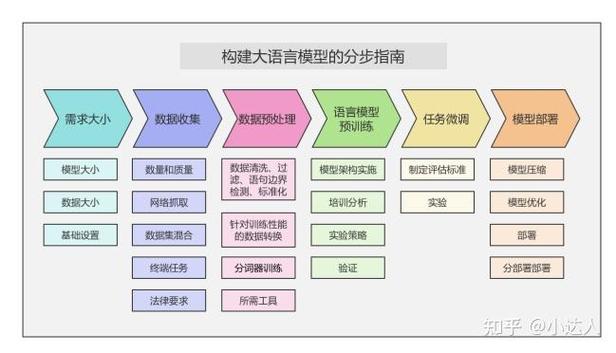
接下来是数据收集与处理,高质量的数据是训练优秀语言模型的基础,数据通常来源于公开语料库、书籍、文章或其他文本资源,这些数据需要经过清洗、去重和格式化,以确保一致性和可用性,数据处理阶段还包括分词、标记化等步骤,将文本转换为模型可理解的数值表示。
模型架构选择是另一个关键环节,Transformer架构因其在序列建模中的卓越表现而成为主流,该架构利用自注意力机制捕捉文本中的长距离依赖关系,从而提升模型的理解和生成能力,基于Transformer的模型,如GPT系列和BERT,已在自然语言处理领域取得显著成果。
训练过程是资源密集型的阶段,模型通过大量文本数据进行学习,逐步调整参数以最小化预测误差,这一过程通常需要强大的计算资源,包括高性能GPU或TPU,训练时间可能从数天到数周不等,具体取决于数据规模和模型复杂度。
模型评估与优化同样重要,开发人员使用多种指标,如困惑度、准确率和F1分数,来衡量模型性能,根据评估结果,可能需要对模型进行微调或结构调整,以提升其效果和泛化能力。

部署与维护是确保模型实际应用的关键,模型需要集成到现有系统中,并提供持续的监控和更新,以应对数据分布变化或用户需求调整。
从技术角度看,AI语言模型的制作融合了计算机科学、语言学和统计学的多学科知识,其发展不仅体现了算法和硬件的进步,也反映了对数据质量和模型可解释性的持续探索,随着技术的演进,语言模型有望在更多领域发挥重要作用,同时仍需关注其伦理和社会影响。

 13888888888
13888888888

 点击咨询
点击咨询 