在人工智能技术快速发展的当下,手部模型的训练已成为计算机视觉领域的一个重要研究方向,从虚拟现实交互到手势控制设备,从手语识别到医疗康复辅助,高精度的手部动作捕捉与生成模型正逐渐应用于多个实际场景,如何训练一个表现稳定、泛化能力强的手部模型,是许多研究者与工程师关注的焦点。
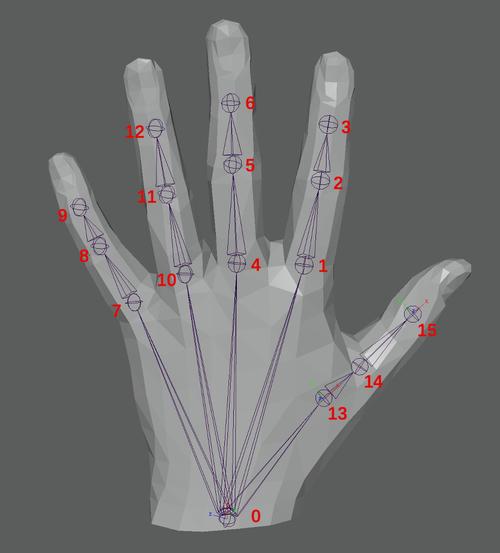
训练手部模型的核心挑战在于手部结构的复杂性,人手具有二十七个自由度,包括关节弯曲、手指展开、手腕旋转等多种运动形态,且不同人手的大小、形状、皮肤纹理差异显著,遮挡、光照变化、拍摄角度等因素也增加了模型训练的难度,构建一个鲁棒的手部模型不仅需要高质量的数据,也依赖合理的算法设计与训练策略。
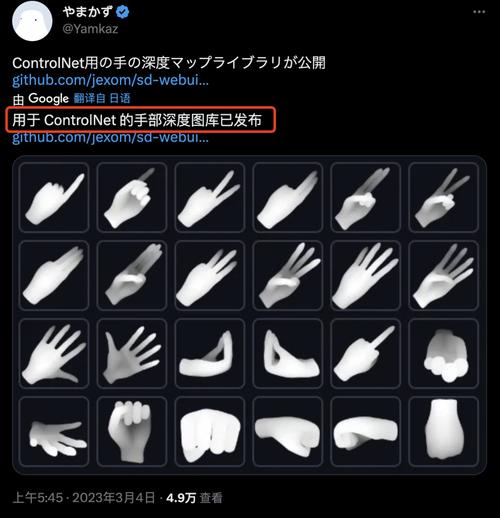
训练的第一步是数据准备,高质量的训练数据是模型成功的基础,目前常用的数据集包括真实捕捉数据和合成数据两大类,真实数据通常通过多视角相机、深度传感器或数据手套采集,能提供丰富的真实手部运动信息,但其制作成本较高且标注复杂,合成数据则通过三维建模软件生成,可以灵活控制手部形态与运动,有效补充真实数据中难以覆盖的边缘场景,在实际训练中,往往需要将两类数据结合使用,以提高模型泛化能力。
模型架构的选择直接影响最终性能,当前主流方法多基于深度学习,尤其是卷积神经网络(CNN)和变换器(Transformer)结构,CNN擅长提取局部视觉特征,适用于手部关键点检测和姿态估计;而Transformer凭借其强大的序列建模能力,更适合处理手部动作的时序关系,一些研究还尝试将图神经网络(GNN)应用于手部骨骼建模,显式利用关节之间的拓扑关系,进一步提升预测稳定性。

训练过程中的损失函数设计也尤为关键,除了常见的关节点坐标误差外,还需考虑生理约束,例如手指长度不变性、关节角度限制、左右手对称性等,引入这些约束可以有效避免模型输出不合理的手部形态,使其更符合生物力学特性,对抗训练、自监督学习等策略也被广泛采用,以提升模型在复杂环境中的鲁棒性。
优化与迭代是训练过程中不可缺少的环节,由于手部模型对精度要求极高,往往需要多次调参和验证,学习率调度、梯度裁剪、正则化等技术有助于稳定训练过程,防止过拟合,使用数据增强方法,如随机旋转、缩放、调整亮度对比度,可以显著提升模型应对真实场景多样性的能力。
评估阶段需综合多项指标,不仅关注关节点误差,还要检查视觉效果和运动连贯性,常用的定量指标包括平均关节误差、方差以及不同手势类别的识别准确率;而定性的评估则依赖于可视化结果和用户研究,确保生成的手部动作自然合理。
尽管当前手部模型已取得显著进展,但仍存在一些尚未完全解决的问题,例如极端遮挡下的恢复能力、细微手势的区分度以及跨用户的适应性,未来的研究可能会更注重多模态融合,结合视觉与惯性测量单元(IMU)数据,或利用更强的大规模预训练模型提升泛化性能。
从技术实践的角度来看,训练一个可用且可靠的手部模型需要扎实的理论知识、充分的计算资源和细致的实验设计,它不仅是一个算法问题,更是一个系统工程,需在不断迭代中平衡精度、效率与实用性,对于开发者而言,理解整个流程的细节与难点,将有助于更好地应用和优化手部建模技术,推动其在实际场景中的落地。

 13888888888
13888888888

 点击咨询
点击咨询 