人工智能人物模型的训练是一个充满挑战又极具吸引力的领域,作为网站站长,我经常收到关于如何构建这类模型的咨询,我想和大家分享一些实用的方法,帮助您理解从零开始训练一个AI人物模型的过程,无论您是初学者还是有一定经验的开发者,这些内容都能提供有价值的参考。
我们需要明确什么是AI人物模型,它是一种基于机器学习的技术,能够生成或识别人类特征,例如面部表情、语音或行为模式,这类模型广泛应用于虚拟助手、游戏角色、影视制作和个性化推荐系统中,训练一个高质量的模型,关键在于数据、算法和迭代优化。
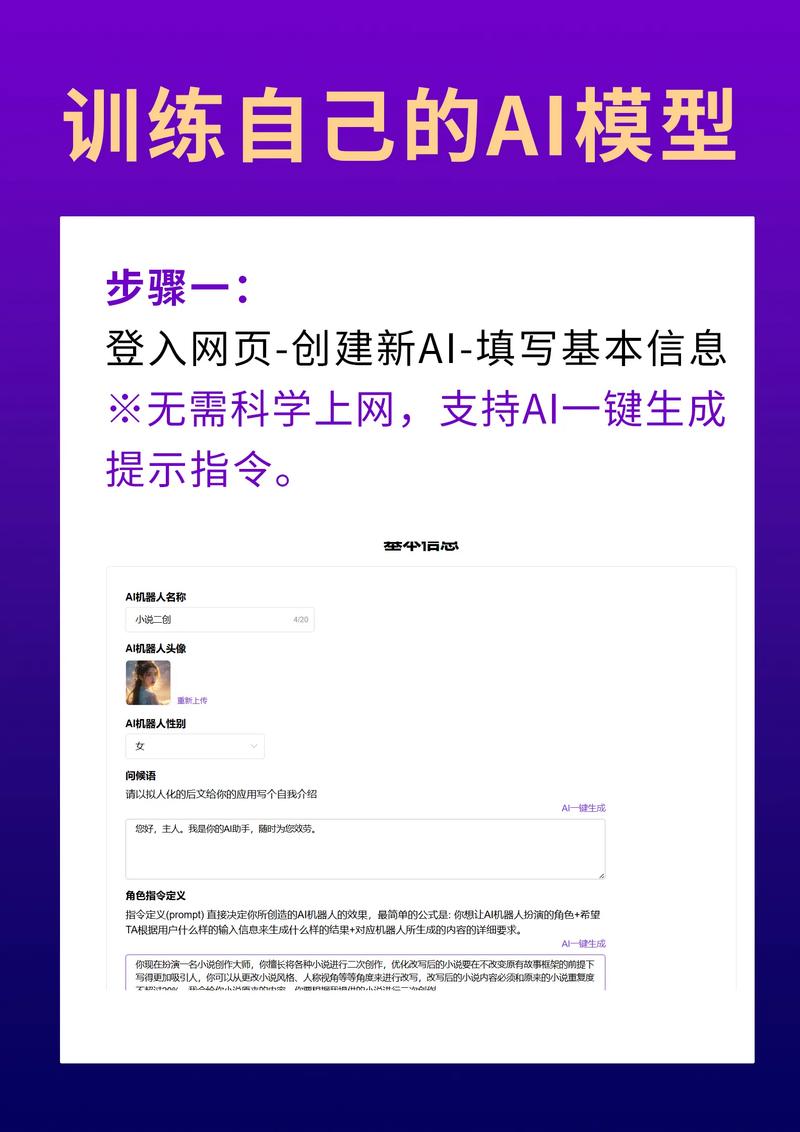
数据准备是训练过程的基石,没有高质量的数据,模型很难达到预期效果,收集数据时,应选择多样化的来源,例如公开数据集或自定义采集,如果您想训练一个生成人脸图像的模型,可能需要数千张不同角度、光照和表情的图片,数据预处理包括清洗、标注和增强,清洗可以去除噪声和无关信息;标注则为数据添加标签,方便模型学习;增强技术如旋转、缩放或颜色调整,能有效提升数据的丰富性,防止模型过拟合,数据质量直接决定模型的上限,因此投入足够时间在这一步非常必要。
接下来是模型选择,当前流行的AI人物模型包括生成对抗网络(GAN)、变分自编码器(VAE)和扩散模型,GAN通过生成器和判别器的对抗训练,能产生逼真的图像;VAE则侧重于学习数据的潜在分布,适合生成平滑的变体;扩散模型近年来兴起,通过逐步去噪过程生成高质量输出,选择模型时,需考虑项目需求:如果追求高真实感,GAN或扩散模型可能更合适;如果注重稳定性和可控性,VAE值得尝试,预训练模型可以加速过程,例如使用在大型数据集上训练好的基础模型进行微调。
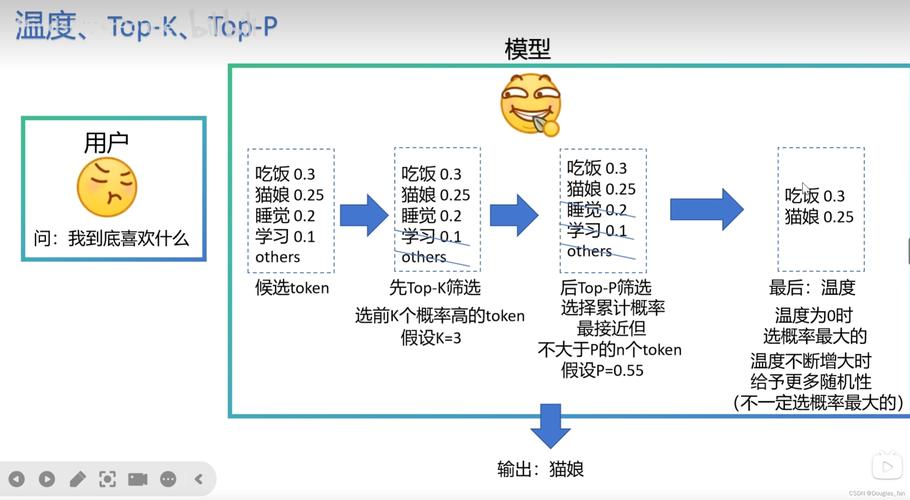
训练过程本身涉及多个步骤,我们从初始化模型参数开始,然后进入迭代训练,在每次迭代中,模型接收输入数据,计算损失函数(如交叉熵或均方误差),并通过反向传播更新权重,优化器如Adam或SGD用于调整学习率,确保收敛稳定,训练时,监控指标如准确率、F1分数或生成图像的清晰度至关重要,如果损失值波动大或指标停滞,可能需要调整超参数,例如批量大小或学习率,实践中,分布式训练可以加速过程,尤其当数据量庞大时。
评估和调优是确保模型实用的环节,训练完成后,使用验证集测试模型性能,避免在测试集上过拟合,常见评估方法包括视觉检查、定量指标(如IS分数或FID)和用户反馈,如果模型生成的人物图像模糊或失真,可能是数据不足或模型复杂度不够;这时,可以增加数据量或调整网络结构,关注偏差问题:如果训练数据缺乏多样性,模型可能对某些群体表现不佳,通过数据平衡和正则化技术,可以缓解这一问题。

在训练中,常会遇到挑战,例如计算资源限制或模型不收敛,针对这些,我建议从小规模开始,逐步扩展,使用云服务平台可以灵活调配资源;早停法和学习率调度能帮助避免过训练,更重要的是,保持耐心和迭代思维:AI模型训练很少一蹴而就,需要多次实验和调整。
从个人视角看,AI人物模型的训练不仅是技术活,更是一门艺术,它融合了创意和逻辑,让我们能探索人类特征的无限可能,随着多模态模型和伦理框架的发展,这一领域将更加成熟,我相信,注重数据隐私和模型可解释性,会推动行业走向更负责任的方向,如果您正在尝试,不妨从简单项目入手,积累经验后再挑战复杂任务,每一次训练都是一次学习的机会,坚持下去,您会看到令人惊喜的成果。

 13888888888
13888888888

 点击咨询
点击咨询 