人工智能算法模型的训练过程,其实就像教一个孩子学习新知识一样,需要耐心、方法和反复实践,作为网站站长,我经常被问到这个问题,今天就来分享一下我的理解,训练AI模型不仅仅是技术活,它还涉及到数据、算法和实际应用的巧妙结合,下面,我将一步步带你了解这个过程,希望能帮助你更好地理解AI是如何“学会”的。
训练AI模型离不开数据,数据是AI的“食粮”,没有高质量的数据,模型就很难学会有用的东西,举个例子,如果你想训练一个识别猫的AI模型,你就需要成千上万张猫的图片,这些数据需要多样化,包括不同品种、姿势和背景的猫,这样才能让模型学会泛化,而不是只记住特定的例子,数据收集通常来自公开数据集、用户生成内容或专业采集,但关键是要确保数据的代表性和真实性,如果数据有偏差,比如只包含某一种猫,模型在实际应用中就可能出错。

接下来是数据预处理,原始数据往往杂乱无章,包含噪声、缺失值或不一致的格式,预处理就像给数据“洗澡”,让它变得干净整齐,常见的步骤包括去除重复数据、标准化数值(比如将像素值缩放到0-1之间)、处理缺失值(用平均值或中位数填充),以及数据增强(例如对图像进行旋转、翻转,以增加多样性),这一步很重要,因为干净的数据能提高训练效率,减少模型过拟合的风险,我经常提醒自己,在AI项目中,数据预处理往往占用了大部分时间,但它决定了模型的最终表现。
我们进入模型选择阶段,AI算法模型有很多种,比如神经网络、决策树或支持向量机,选择哪种取决于具体任务,对于图像识别,卷积神经网络(CNN)很常用;而对于文本分析,循环神经网络(RNN)或Transformer模型可能更合适,模型选择不是随意的,它需要基于问题复杂度、数据量和计算资源来权衡,我们会从预训练模型开始,这能节省时间和资源,就像站在巨人的肩膀上,再根据具体需求进行微调。
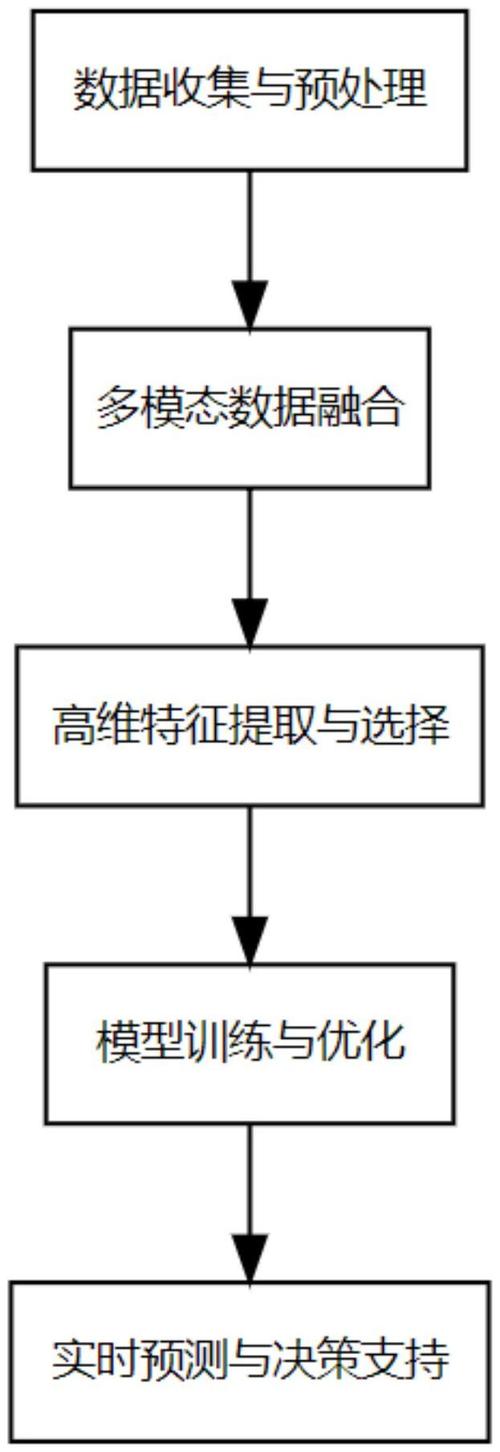
训练过程本身是核心部分,这涉及到将数据输入模型,通过迭代优化来调整模型参数,简单说,模型会先做出预测,然后与实际结果比较,计算出误差(通常用损失函数表示),再通过反向传播算法调整参数,以最小化误差,常用的优化器如随机梯度下降(SGD)或Adam,帮助模型在每次迭代中学习,训练需要大量计算资源,尤其是深度学习模型,可能用到GPU或分布式系统,我注意到,训练过程中监控指标如准确率或损失值很重要,它能及时发现问题,比如如果损失值不下降,可能意味着模型架构或数据有问题。
训练完成后,评估和调优是必不可少的,我们不能只凭训练数据判断模型好坏,因为它可能过拟合(即只记住训练数据,而无法泛化到新数据),我们会用未见过的测试数据来评估性能,常用指标包括准确率、精确率、召回率或F1分数,如果表现不佳,就需要调优,比如调整超参数(学习率、层数)、增加数据量或尝试不同模型架构,这个过程可能反复多次,就像打磨一件艺术品,直到它达到理想状态。
部署和维护模型是实际应用的关键,训练好的模型需要集成到系统中,并持续监控其表现,因为现实世界的数据会变化,模型可能需要定期更新,一个推荐系统如果用户行为变了,模型就得重新训练以适应新趋势。
从我的经验来看,AI模型训练不仅仅是技术操作,它还体现了人类对智能的探索,每一步都需要严谨和创意,尤其是数据质量和模型选择,往往比算法本身更重要,随着自动化工具的发展,训练过程可能会更高效,但核心原理不会变——那就是通过数据驱动,让机器学会理解和决策,作为站长,我认为理解这些基础,能帮助我们在AI时代更好地把握机会,避免盲目跟风,毕竟,AI不是魔法,而是建立在扎实的工作之上。

 13888888888
13888888888

 点击咨询
点击咨询 